TRANSIC: Sim-to-Real Policy Transfer by Learning from Online Correction
An RL sim-to-real policy trained with TRANSIC successfully completes a long-horizon and contact-rich task: assembling a table lamp from scratch.
An RL sim-to-real policy trained with TRANSIC successfully completes a long-horizon and contact-rich task: assembling a table lamp from scratch.

Conference on Robot Learning (CoRL) 2024
Learning in simulation and transferring the learned policy to the real world has the potential to enable generalist robots. The key challenge of this approach is to address simulation-to-reality (sim-to-real) gaps. Previous methods often require domain-specific knowledge a priori. We argue that a straightforward way to obtain such knowledge is by asking humans to observe and assist robot policy execution in the real world. The robots can then learn from humans to close various sim-to-real gaps. We propose TRANSIC, a data-driven approach to enable successful sim-to-real transfer based on a human-in-the-loop framework. TRANSIC allows humans to augment simulation policies to overcome various unmodeled sim-to-real gaps holistically through intervention and online correction. Residual policies can be learned from human corrections and integrated with simulation policies for autonomous execution. We show that our approach can achieve successful sim-to-real transfer in complex and contact-rich manipulation tasks such as furniture assembly. Through synergistic integration of policies learned in simulation and from humans, TRANSIC is effective as a holistic approach to addressing various, often coexisting sim-to-real gaps. It displays attractive properties such as scaling with human effort.
At a high level, after training the base policy in simulation, we deploy it on the real robot while monitored by a human operator. The human interrupts the autonomous execution when necessary and provides online correction through teleoperation. Such intervention and online correction are collected to train a residual policy, after which both base and residual policies are deployed to complete contact-rich manipulation tasks.
(a) Base policies are first trained in simulation through action space distillation with demonstrations generated by RL teacher policies. Base policies take point cloud as input to reduce perception gap. (b) The acquired base policies are first deployed with a human operator monitoring the execution. The human intervenes and corrects through teleoperation when necessary. Such correction data are collected to learn residual policies. Finally, both residual policies and base policies are integrated during test time to achieve a successful transfer.
Our key insight is that the human-in-the-loop framework is promising for addressing the sim-to-real gaps as a whole, in which humans directly assist the physical robots during policy execution by providing online correction signals. The knowledge required to close sim-to-real gaps can be learned from human signals.
Simulation policies are deployed where a human operator monitors the execution. The human intervenes and corrects through teleoperation when necessary. Such intervention and correction data are collected to learn residual policies. Finally, both residual policies and simulation policies are integrated during test time to achieve successful transfer.
Using the state-of-the-art simulation technique, we train base policies in simulation with hundreds of thousands of frames per second. This greatly alleivates the human burden for data collection. We first train teacher policies with model-free reinforcement learning (RL) on massively parallelized environments. We then distill RL teacher policies into student visuomotor policies.
For each manipulation skill, we first train an RL policy and then distill into a visuomotor policy. We apply domain randomization such that trained simulation policies are robust enough. Several important design choices are made to facilitate sim-to-real transfer, such as taking point cloud inputs and adopting joint position actions.
We use point cloud as the main visual modality. Typical RGB observation used in visuomotor policy training
suffers from several drawbacks that hinder successful transfer. Well-calibrated point cloud observation can
bypass these issues.
We first train the teacher policy with OSC for the ease of learning and then distill successful
trajectories into the student policy with joint position control. We name this approach as action space
distillation and find it crucial to overcome the sim-to-real controller gap.
We use point cloud as the main visual modality. Simulation polices are trained on downsampled synthetic point-cloud observations. They are able to transfer to real-world point-cloud observations captured by standard depth cameras.
We seek to answer the following research questions with our experiments:
Q1: Does TRANSIC lead to better transfer
performance while require less real-world data?
Q2: How effective can TRANSIC address
different types of sim-to-real gaps?
Q3: How does TRANSIC scale with human effort?
Q4: Does TRANSIC exhibit intriguing
properties, such as generalization to unseen objects, policy robustness,
ability to solve long-horizon tasks, and other emergent behaviors?
We consider complex contact-rich manipulation tasks in FurnitureBench that require high precision. Specifically, we divide the assembly of a square table into four independent tasks: Stabilize, Reach and Grasp, Insert, and Screw.
Average success rates over four benchmarked tasks. TRANSIC significantly outperforms three baseline groups. They are 1) traditional sim-to-real approaches, such as domain randomization and data augmentation (“DR. & Data Aug.”) and real-world fine-tuning; 2) interactive imitation learning methods, such as HG-Dagger and IWR; and 3) approaches that only train on real-robot data, such as BC, BC-RNN, and IQL. Results are success rates averaged over four tasks. Each evaluation consists of 20 trials with different initial settings. We make our best efforts to ensure the same initial configuration when evaluating different methods.

Success rates per tasks. TRANSIC outperforms all baseline methods on all four tasks.
We show that in sim-to-real transfer, a good base policy learned from the simulation can be combined with limited real-world data to achieve success. However, effectively utilizing human correction data to address the sim-to-real gap is challenging, especially when we want to prevent catastrophic forgetting of the base policy (Q1).
While TRANSIC is a holistic approach to address multiple sim-to-real gaps simultaneously, we shed light on its ability to close each individual gap. To do so, we create five different simulation-reality pairs. For each of them, we intentionally create large gaps between the simulation and the real world. These gaps are applied to the real-world setting and they include perception error, underactuated controller, embodiment mismatch, dynamics difference, and object asset mismatch.
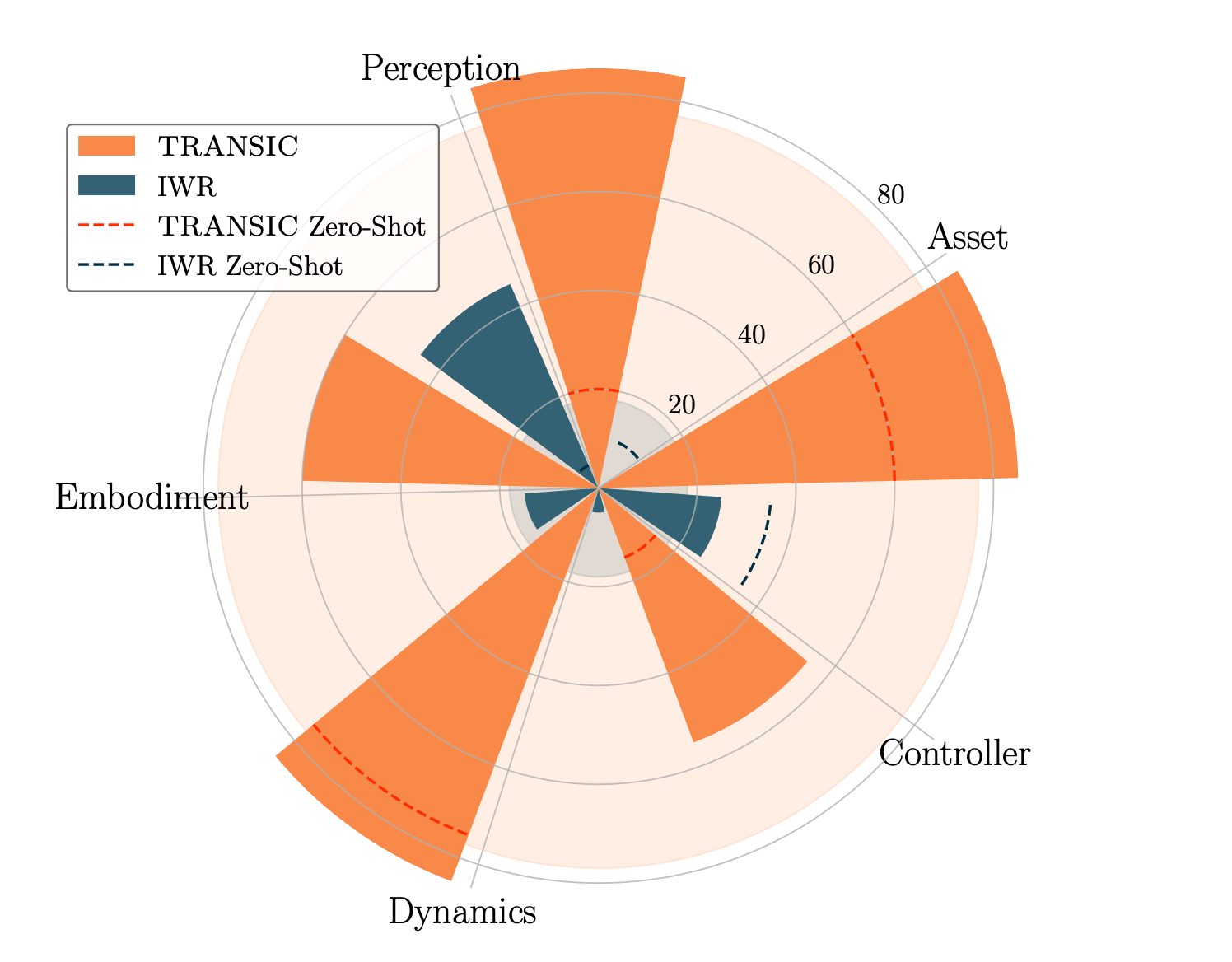
Robustness to different sim-to-real gaps. Numbers are averaged success rates (%). Polar bars represent performances after training with data collected specifically to address a particular gap. Dashed lines are zero-shot performances. Shaded circles show average performances across five pairs.
TRANSIC achieves an average success rate of 77% across five different simulation-reality pairs with deliberately exacerbated sim-to-real gaps. This indicates its remarkable ability to close these individual gaps. In contrast, the best baseline method, IWR, only achieves an average success rate of 18%. We attribute this effectiveness in addressing different sim-to-real gaps to the residual policy design.
Scaling with human effort is a desired property for human-in-the-loop robot learning methods. We show that TRANSIC has better human data scalability than the best baseline IWR. If we increase the size of the correction dataset from 25% to 75% of the full dataset size, TRANSIC achieves a relative improvement of 42% in the average success rate. In contrast, IWR only achieves 23% relative improvement. Additionally, IWR performance plateaus at an early stage and even starts to decrease as more human data becomes available. We hypothesize that IWR suffers from catastrophic forgetting and struggles to properly model the behavioral modes of humans and trained robots. On the other hand, TRANSIC bypasses these issues by learning gated residual policies only from human correction.
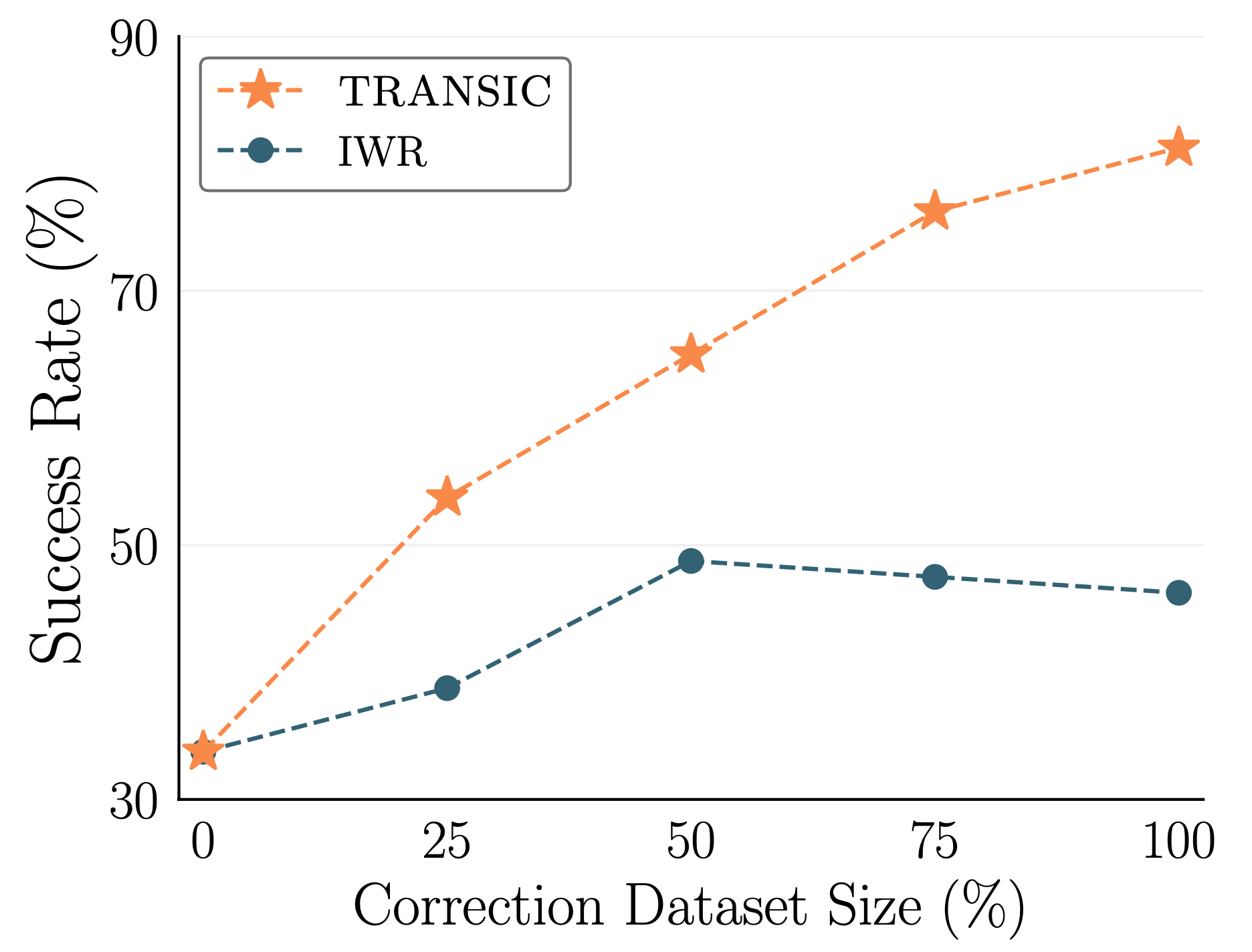
Scalability with human correction data. Numbers are success rates averaged over four tasks with different amount of human correction data.
We further examine TRANSIC and discuss several emergent capabilities. We show that 1) TRANSIC has learned reusable skills for category-level object generalization; 2) TRANSIC can reliably operate in a fully autonomous setting once the gating mechanism is learned; 3) TRANSIC is robust against partial point cloud observations and suboptimal correction data; and 4) TRANSIC learns consistent visual features between the simulation and reality.
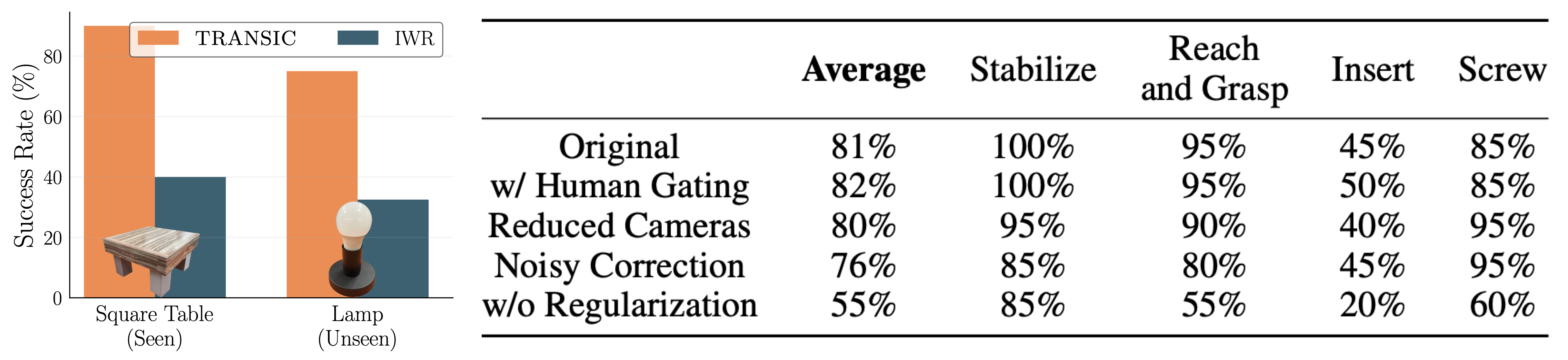
Intriguing properties and emergent behaviors of TRANSIC. Left: Generalization to unseen objects from a new category. Right: The effects of different gating mechanisms (learned gating vs human gating), policy robustness against reduced cameras and suboptimal correction data, and the importance of visual encoder regularization.
Several failure cases. For instances, they include inaccurate insertion, bended gripper, unstable grasping pose, and over-screwing.
In this work, we present TRANSIC, a human-in-the-loop method for sim-to-real transfer in contact-rich manipulation tasks. We show that combining a strong base policy from simulation with limited real-world data can be effective. However, utilizing human correction data without causing catastrophic forgetting of the base policy is challenging. TRANSIC overcomes this by learning a gated residual policy from a small amount of human correction data. We show that TRANSIC effectively addresses various sim-to-real gaps, both collectively and individually, and scales with human effort.
We are grateful to Josiah Wong, Chengshu (Eric) Li, Weiyu Liu, Wenlong Huang, Stephen Tian, Sanjana Srivastava, and the SVL PAIR group for their helpful feedback and insightful discussions. This work is in part supported by the Stanford Institute for Human-Centered AI (HAI), ONR MURI N00014-22-1-2740, ONR MURI N00014-21-1-2801, and Schmidt Sciences. Ruohan Zhang is supported by Wu Tsai Human Performance Alliance Fellowship.
@inproceedings{jiang2024transic,
title = {TRANSIC: Sim-to-Real Policy Transfer by Learning from Online
Correction},
author = {Yunfan Jiang and Chen Wang and Ruohan Zhang and Jiajun Wu and Li
Fei-Fei},
booktitle = {Conference on Robot Learning},
year = {2024}
}